

How does MLFlow help track experiments? I’m not a data scientist; I’m a software engineer, but I enjoy
working with data science teams. One of my favorite things we do at Lofty is to work with data science
teams to help turn their science experiments into applications and products. While doing that we tend to
encounter common problems which are not domain specific. How do we track experiments? How do we
track and compare parameters? How do we keep track of artifacts? Let’s see how MLFlow can help.
MLFlow helps to track ML experiments by giving us some python utility functions
Log parameters.
Log metrics (this can be updated, as you would update a metric throughout an experiment)
# Log a metric; metrics can be updated throughout the run
Log artifacts in a given location
We have a MLFlow Tracking Server deployed to a Kubernetes Cluster which our experiment code base
is configured to communicate with. This is done through environment variables. Once that’s configured,
these utilities provide a clean way to track and compare these results through a built-in User Interface:
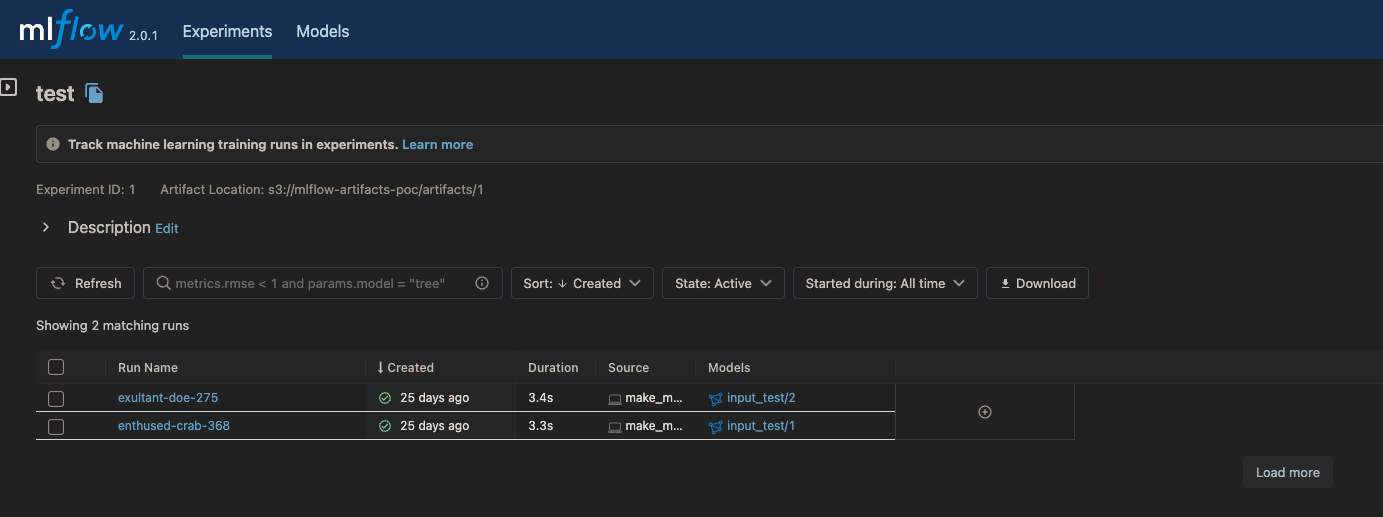
Experiments are assigned a UUID and a unique phrase to help keep track of them. Above, we have a list view of some generated experiment runs.
We can dive deeper into a specific experiment run:

MLFlow has proven to be a valuable tool for tracking experiments which has helped to improve the quality of life for data scientists and help improve their efficiency. MLFlow also gives us tools to store Machine Learning Models in a registry. From this registry they can be deployed as services in several different formats: on bare metal, in a Docker container, etc. MLFlow SDK also makes it possible to quickly and easily reincorporate these models into existing experiment runs without having to deploy them. Perhaps we’ll explore the Model Registry feature of MLFlow in a future post. I know the data science teams we’re working with are happy to have some tools that help them track experiments, while I’m pretty excited about the Model Registry.

.jpg)

